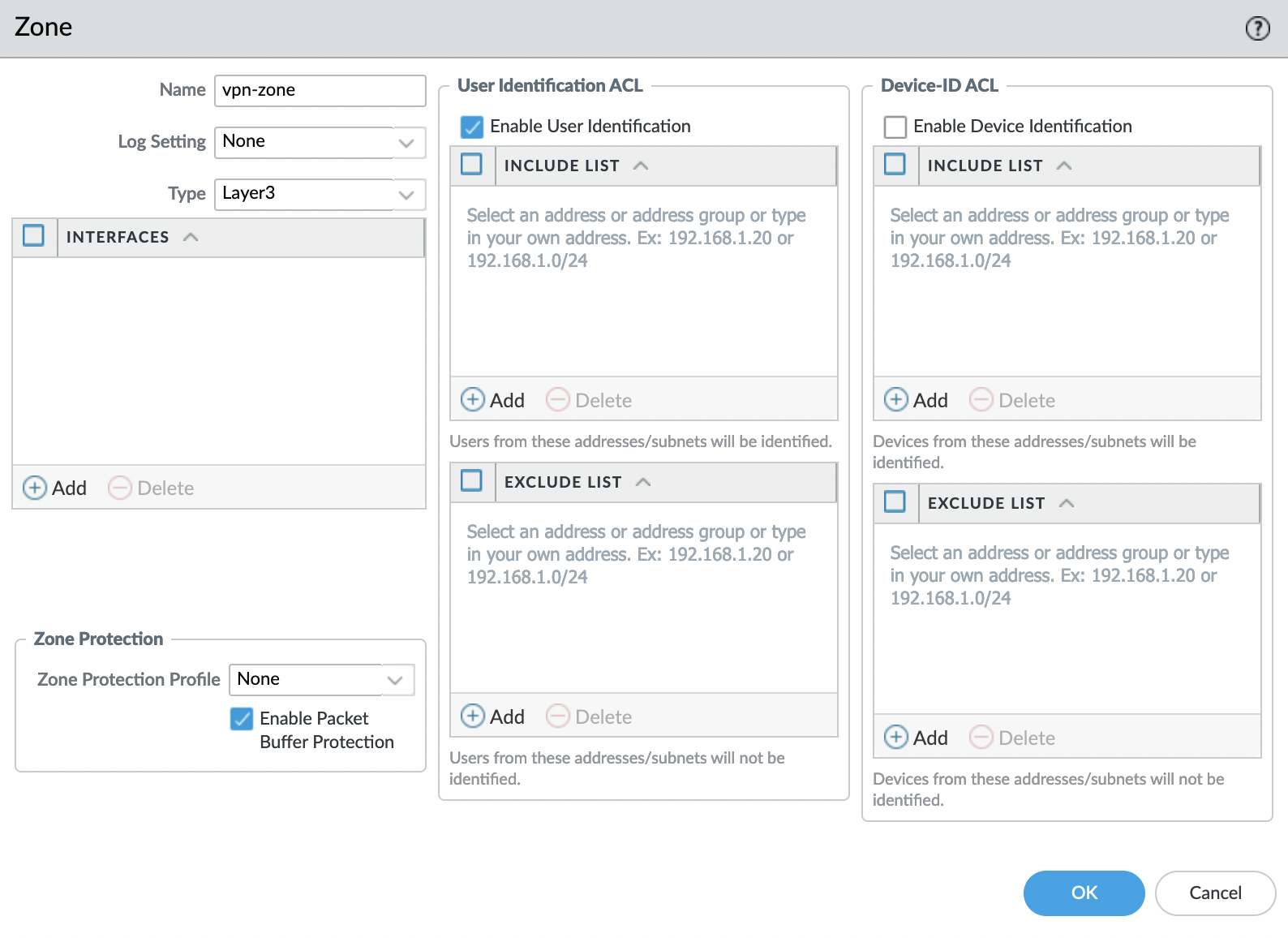
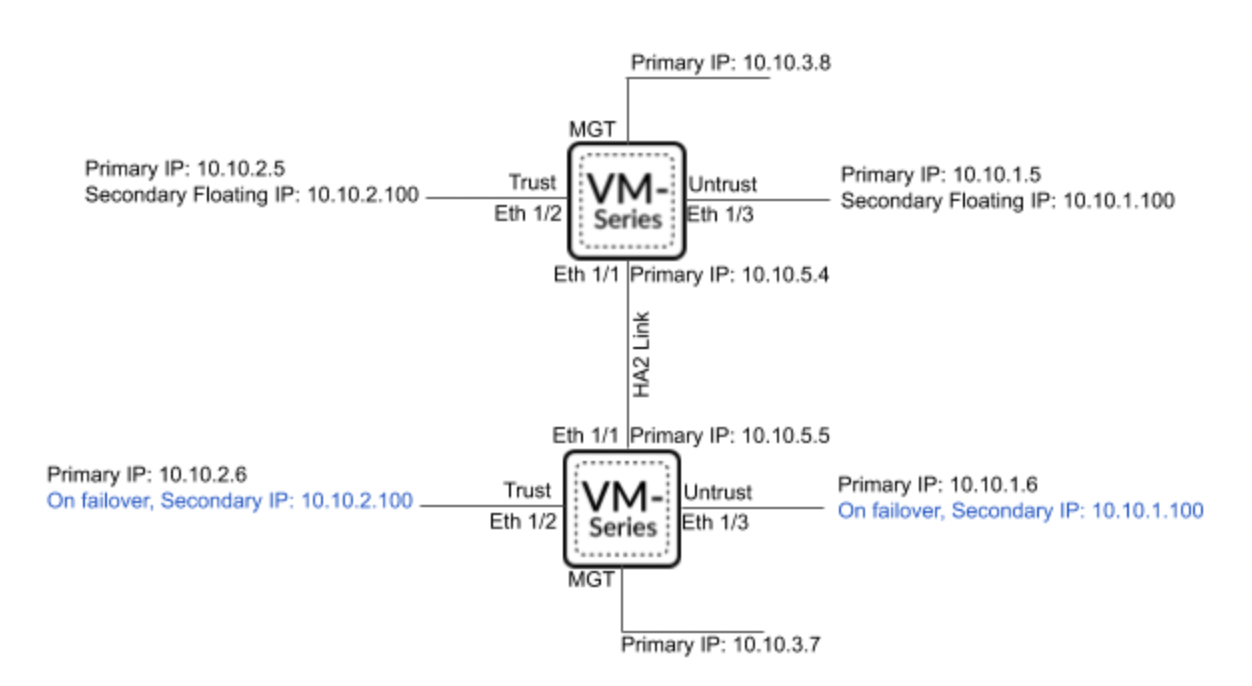
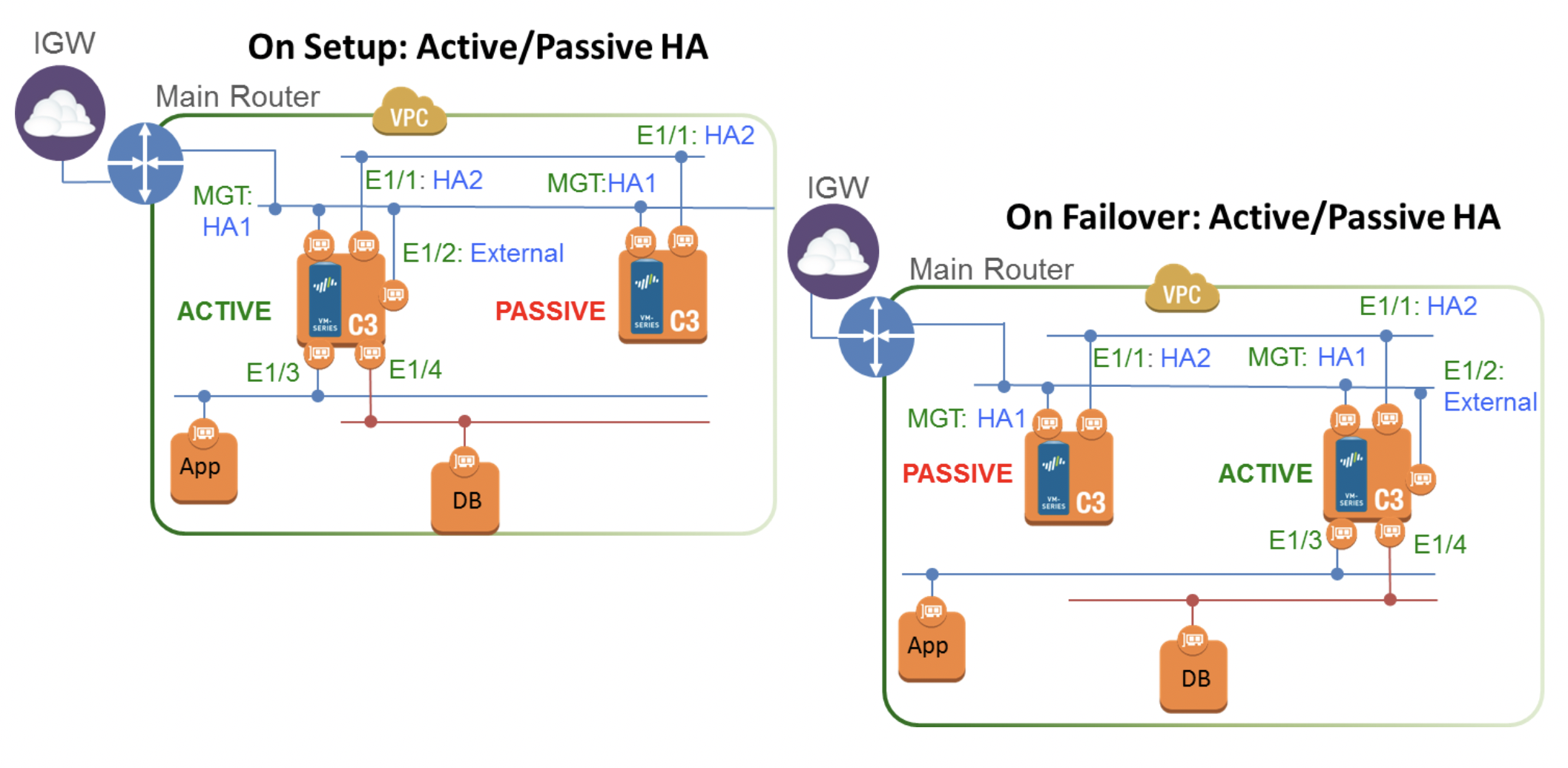
GlobalProtect поддерживает разные способы авторизации, в том числе и SAML 2.0 IdP. В данном примере показана настройка авторизации через AWS SSO.
AWS
Перед тем как добавить SAML IdP у вас должен быть уже настроен AWS Directory Service
Для начала добавим приложение, для этого переходим «IAM Identity Center» -> «Application assignments» -> «Application»
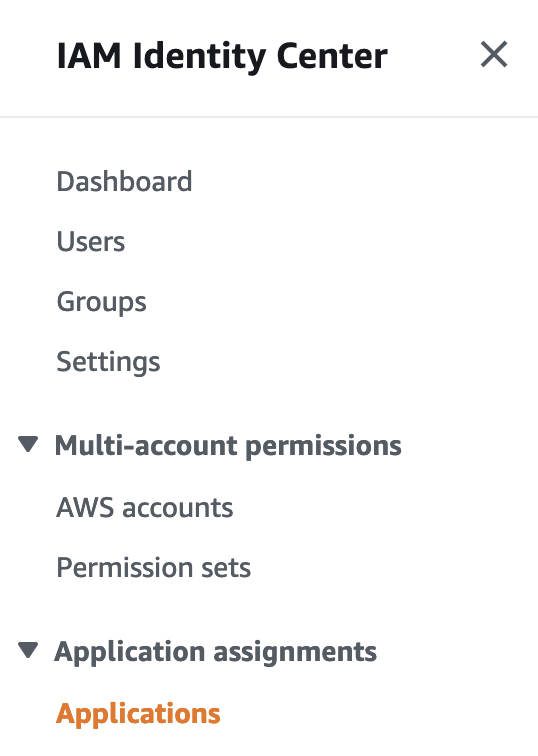
И кликаем «Add Application»

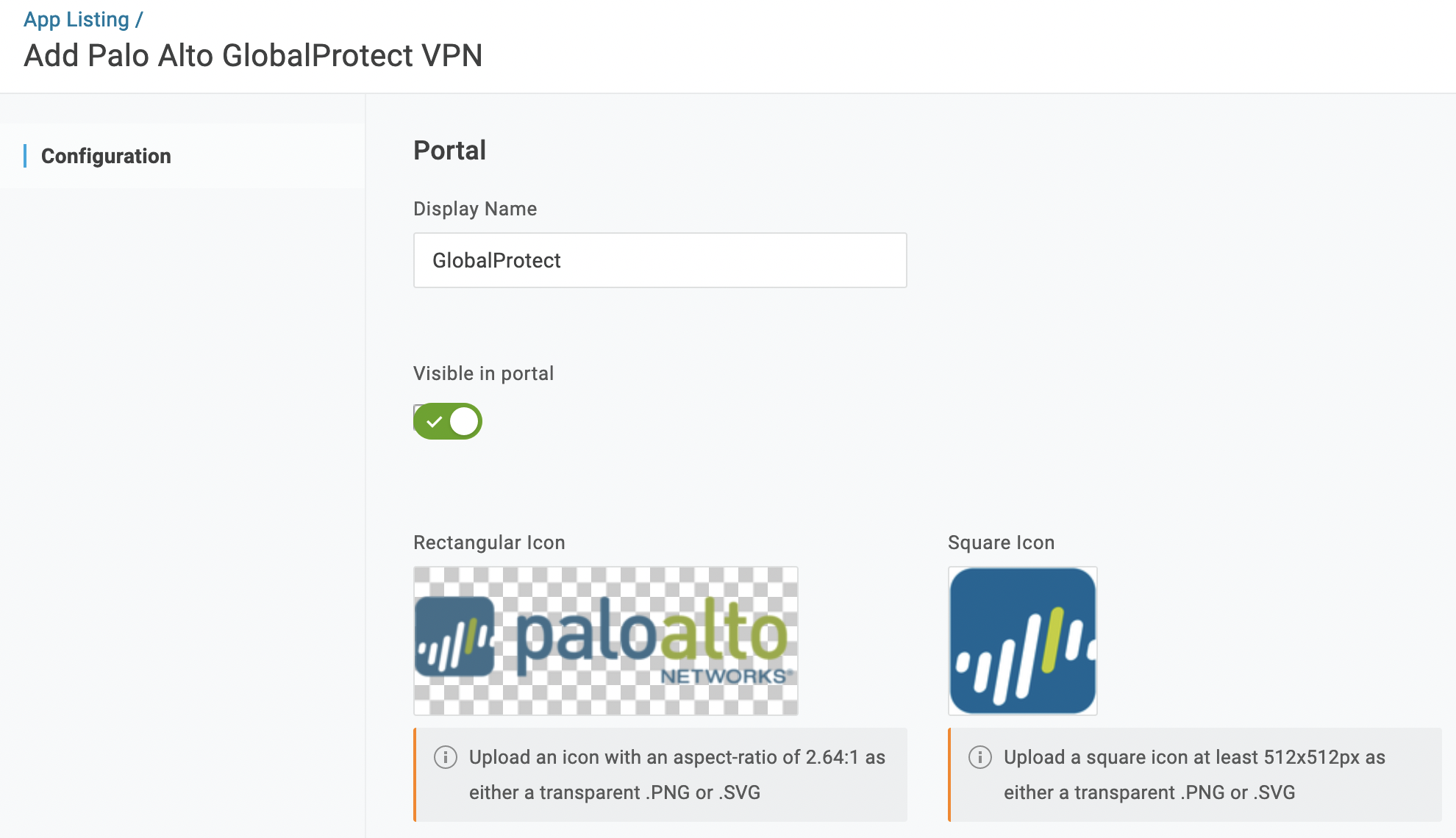
Приложения для GlobalProtect в списке нет, поэтому указываем это будет пользовательское приложение и кликаем «Next»
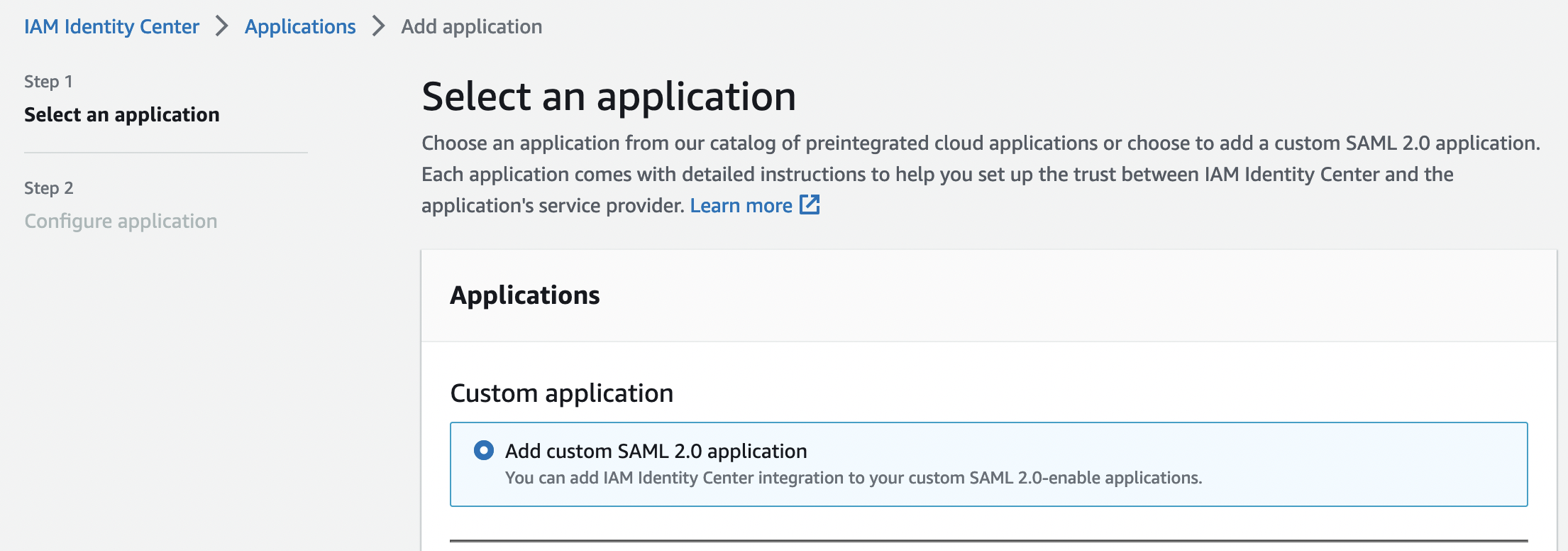
Указываем имя и описание
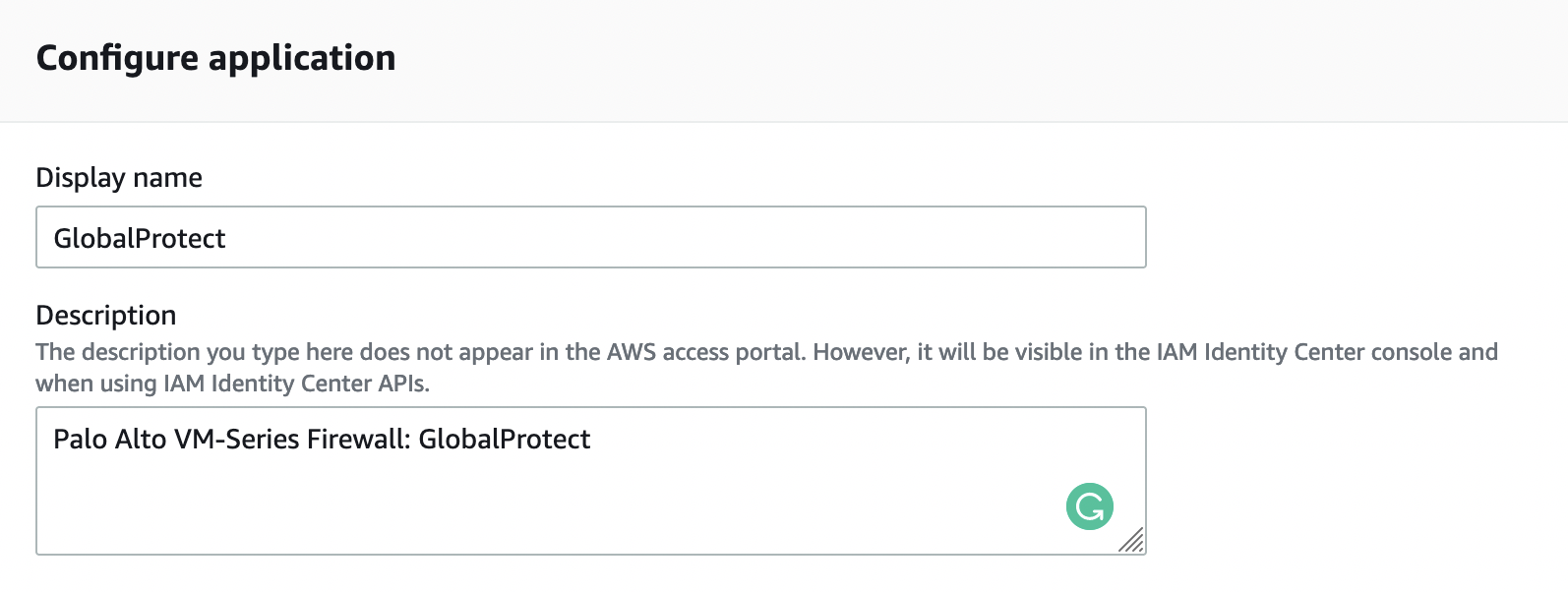
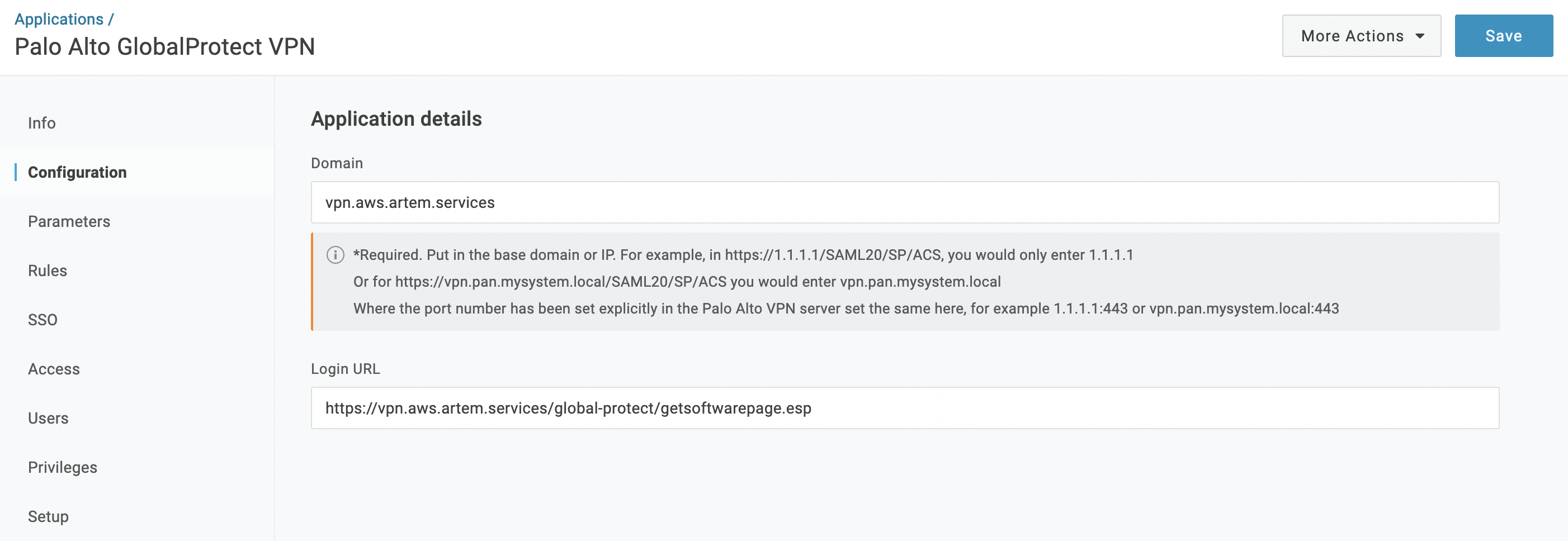
Далее в разделе «Application properties» в поле «Application start URL» указываем следующее:
https://YOUR_GP_DOMAIN/global-protect/getsoftwarepage.esp
Для того, чтобы с портала AWS SSO мы могли попадать на страницу скачивания GlobalProtect клиента
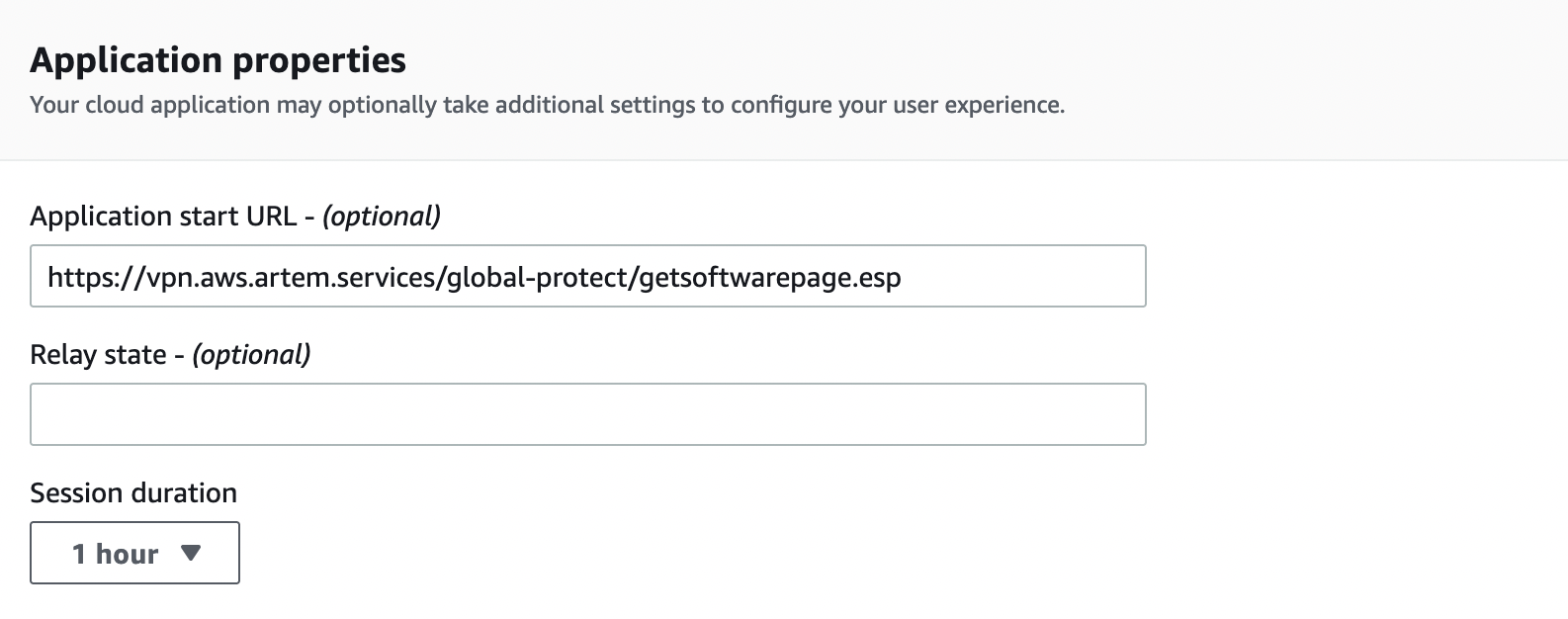
В разделе «Application metadata» в поле «Application ACS URL» указываем следующее:
https://YOUR_GP_DOMAIN:443/SAML20/SP/ACS
И в поле «Application SAML audience«:
https://YOUR_GP_DOMAIN:443/SAML20/SP
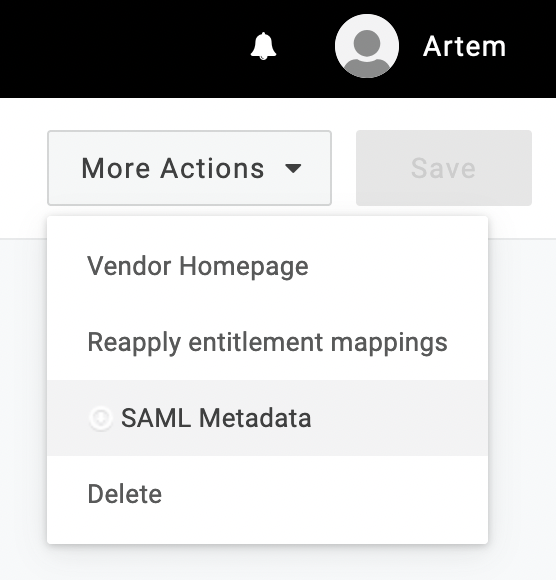
После чего скачиваем SAML Metadata файл, спускаемся вниз и нажимаем «Submit»
После того как добавили приложение нужно убедится, что используется нужный формат аттрибутов. Для этого во вкладке «Actions» выбираем «Edit attribute mapping»
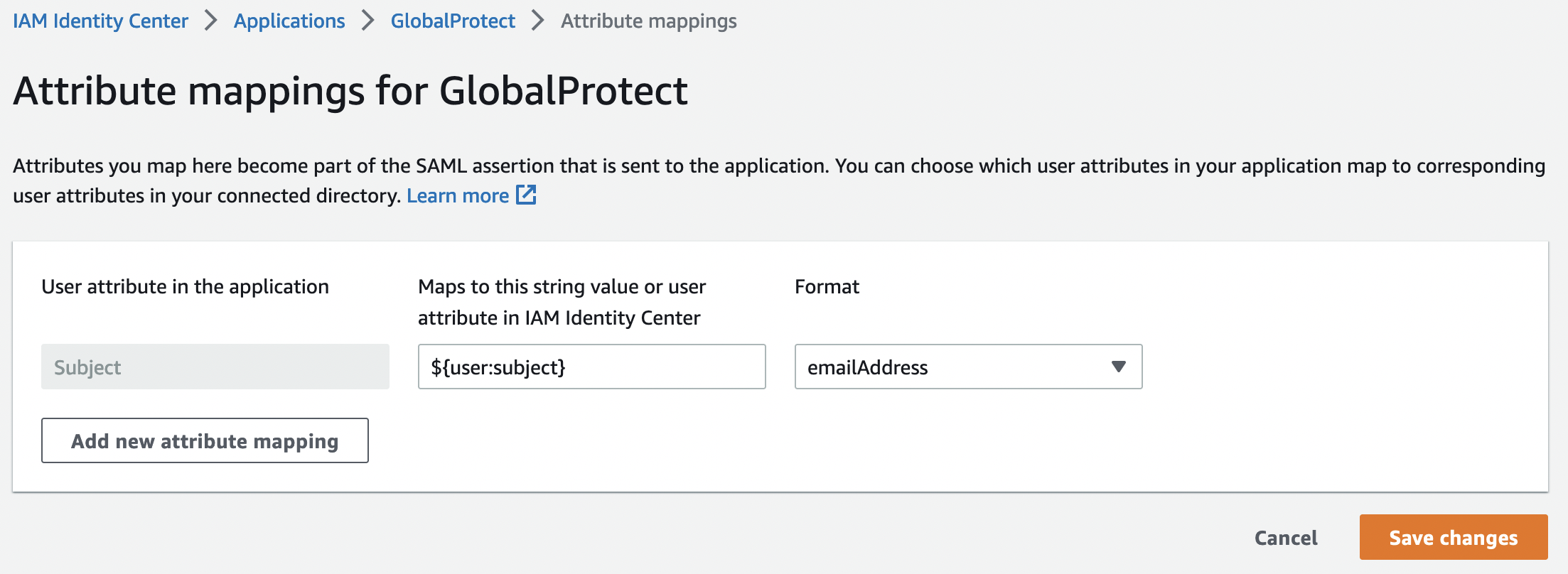
Необходимый формат:
- Value: ${user.subject}
- Format: emailAddress
На этом настройка со стороны AWS завершена.
Firewall
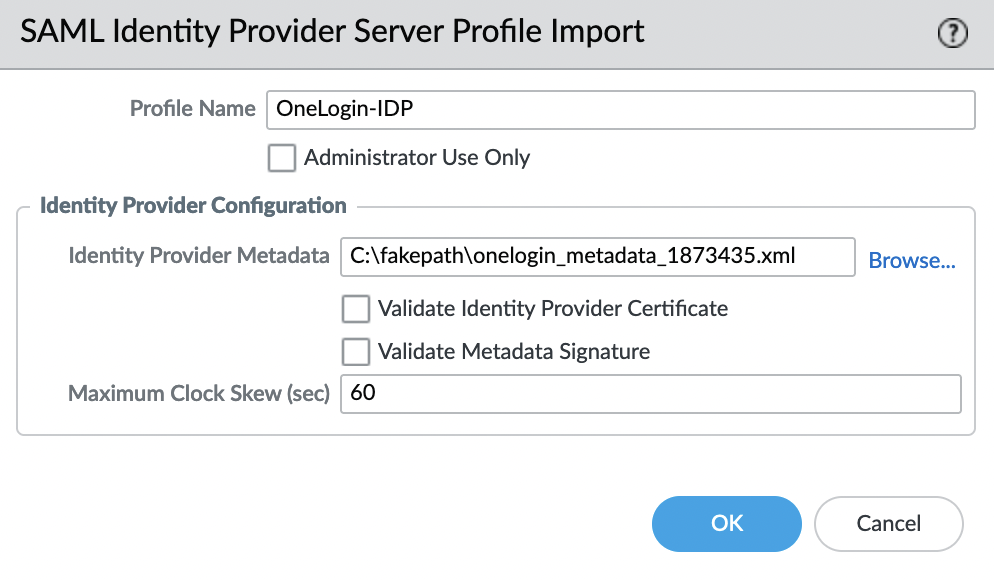
Импортируем SAML Metadata файл, для этого переходим во вкладку «Device» -> «Server Profiles» -> «SAML Identity Provider» и в левом нижнем углу выбираем «Import»
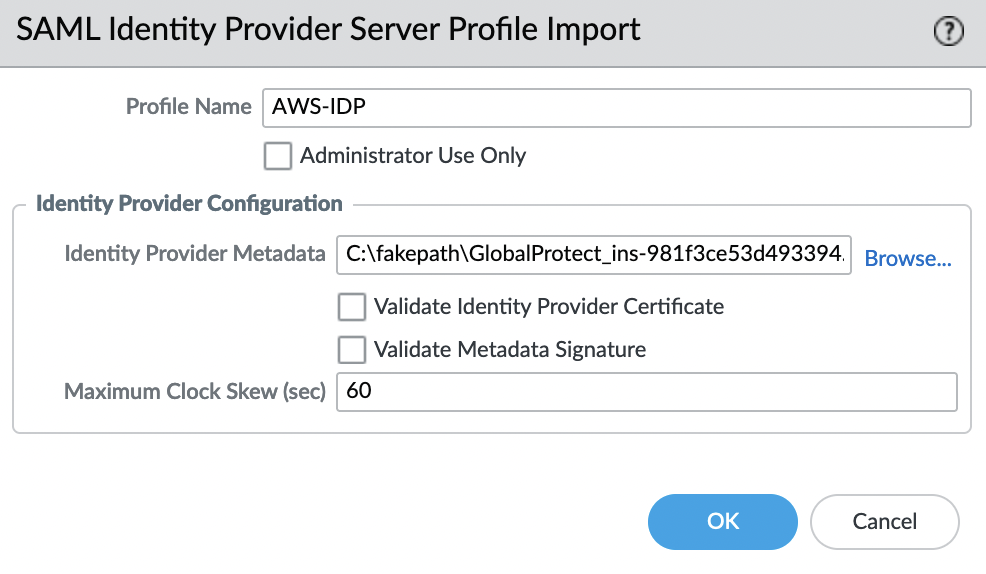
Параметр «Validate Identity Provider Certificate» — должен быть отключен
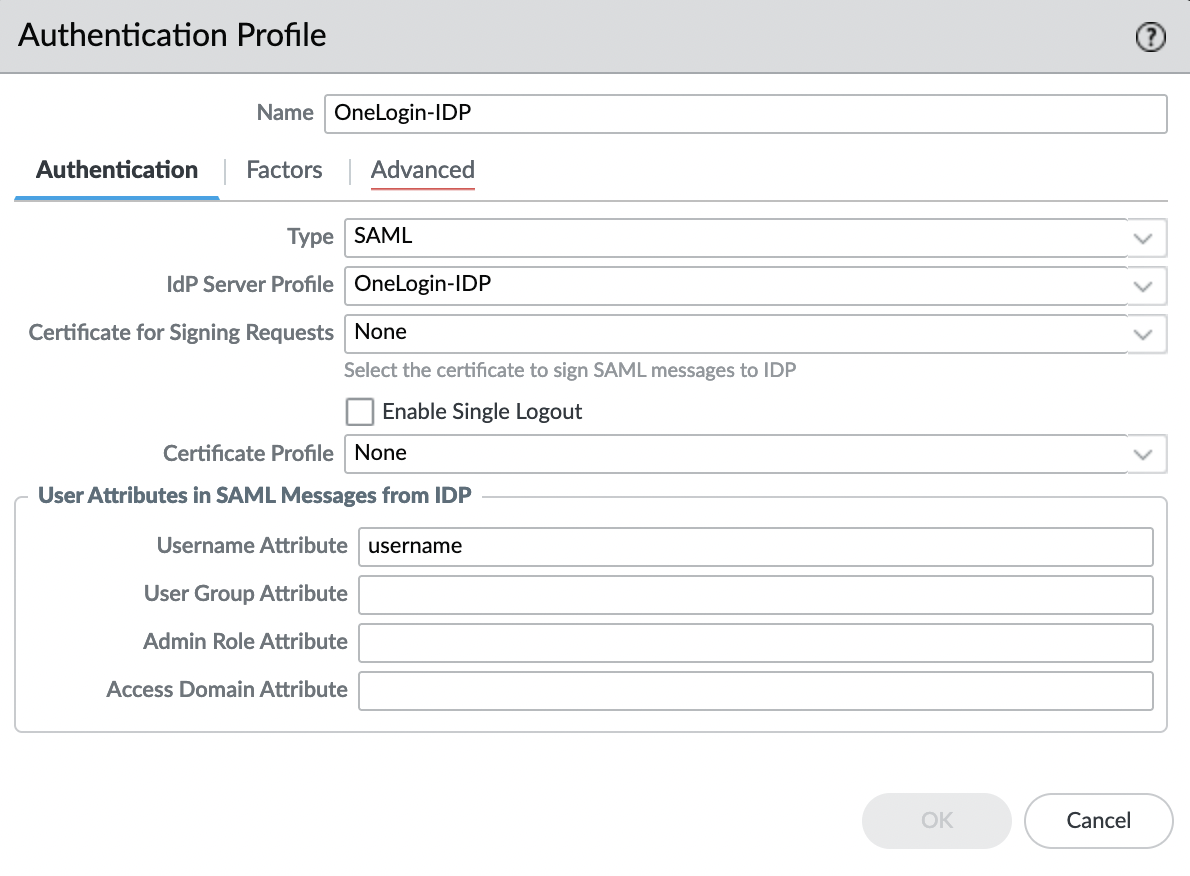
Создадим Authentication Profile, для этого переходим во вкладку «Device» -> «Authentication Profile» и выбираем «Add«. Указываем имя и в поле «IdP Server Profile» выбираем профиль, который импортировали в предыдущем шаге, все остальные настройки оставляем по умолчанию.
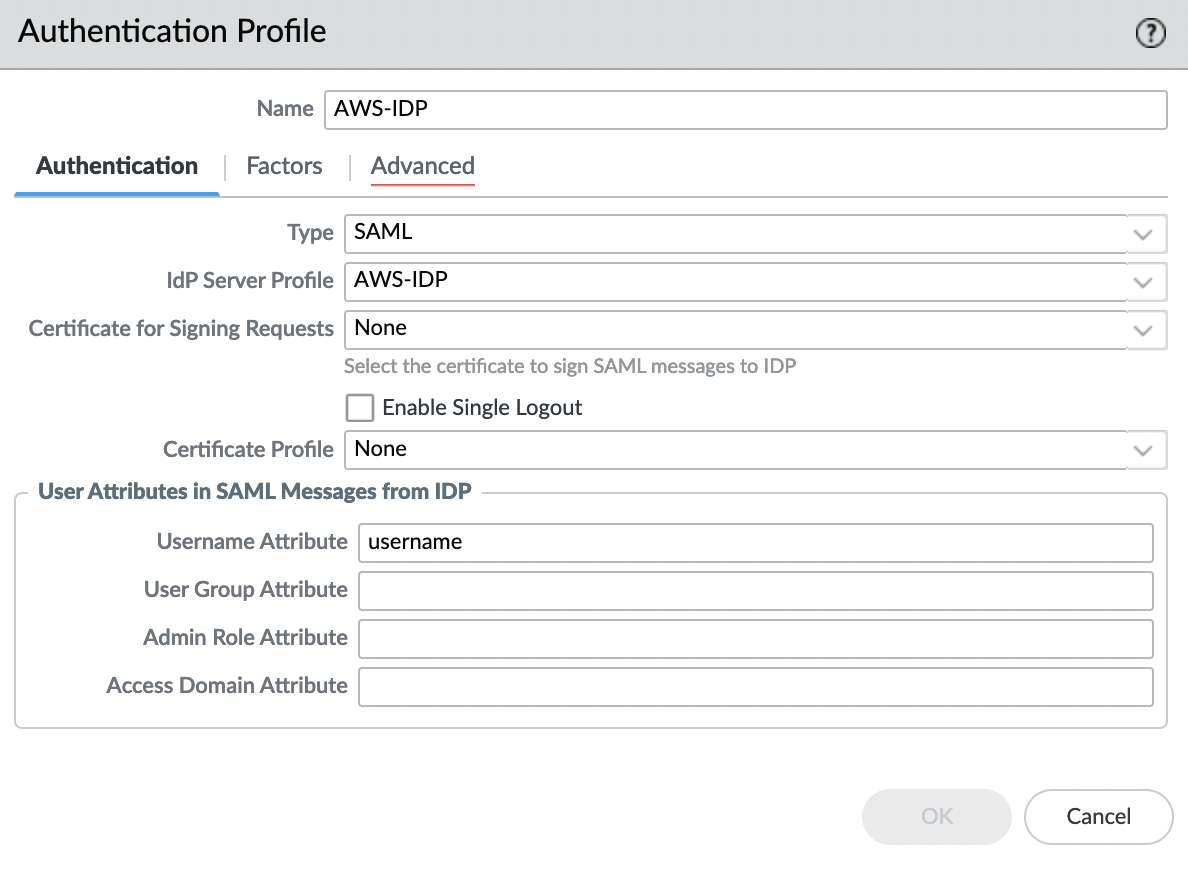
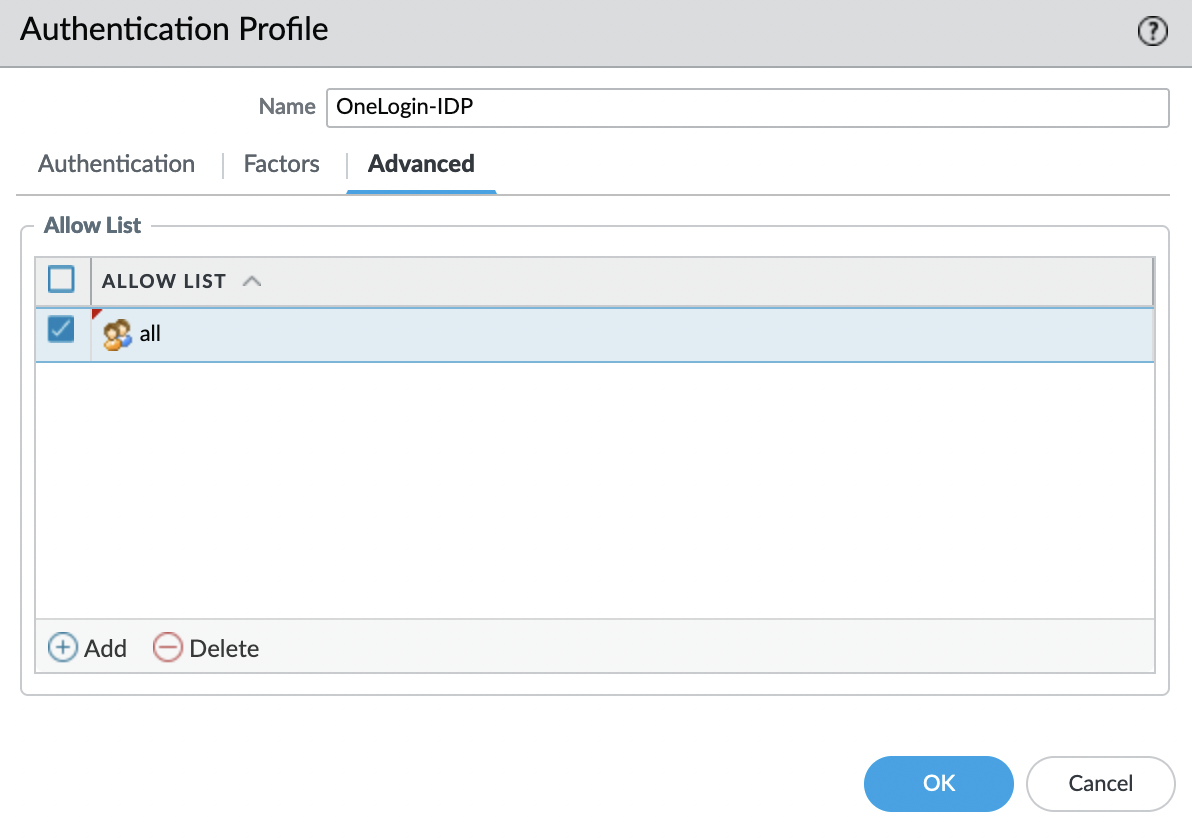
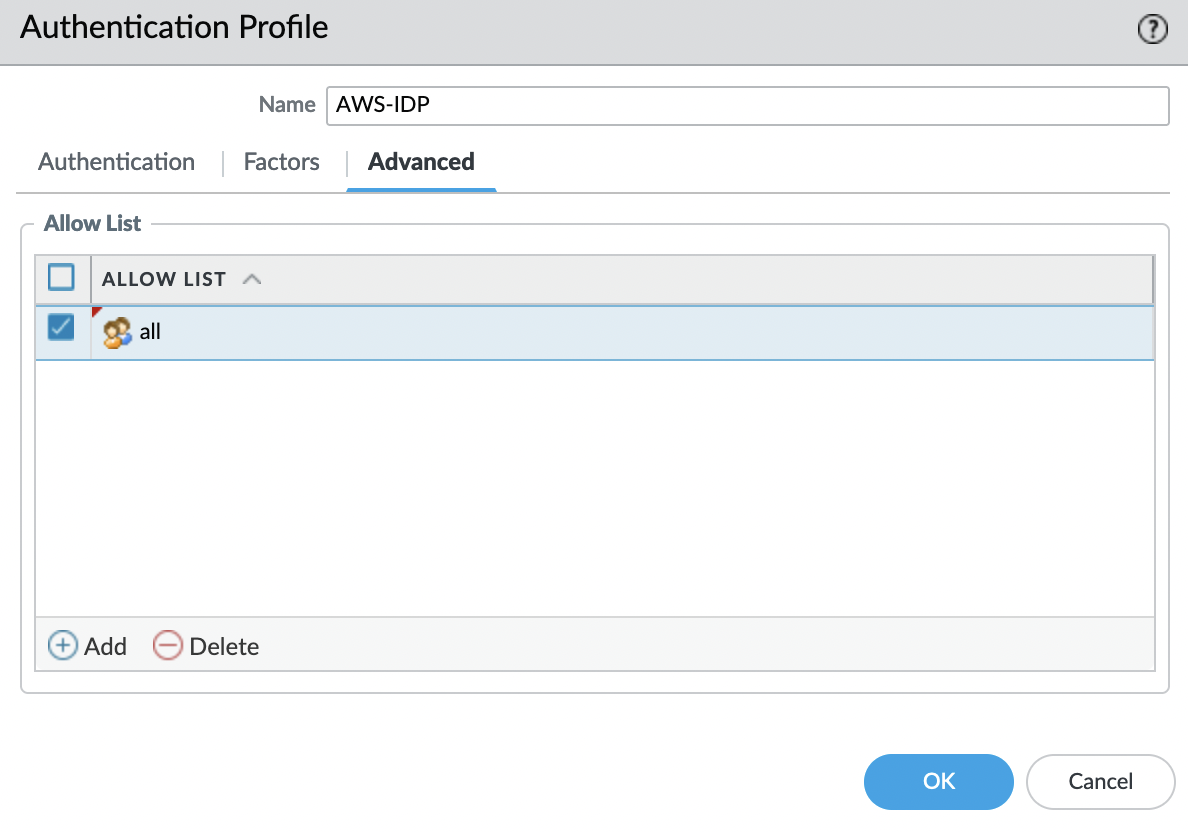
Переходим во вкладку «Advanced» и в «Allow List» добавляем «all«.
Кликаем «OK» и сохраняем изменения, для этого в правом верхнем углу кликаем «Commit«. Теперь мы можем использовать этот Authentication Profile для авторизации в GlobalProtect.