Для выбора версии питона в пайплайне, нужно чтобы нужные версии были установлены в системе.
Дальнейшие действия были выполнены на CentOS 7 и установка бинарников происходила в директорию «/usr/bin/» для удобства, так как в системе уже установлены версии «2.7» и «3.6» из репозитория по данному пути.
Устанавливаем зависимости:
yum install gcc openssl-devel bzip2-devel libffi-devel wget
Скачиваем нужные исходники нужных версий, в данном случае: «3.7«, «3.8» и «3.9»
cd /usr/src
wget https://www.python.org/ftp/python/3.7.9/Python-3.7.9.tgz
wget https://www.python.org/ftp/python/3.8.9/Python-3.8.9.tgz
wget https://www.python.org/ftp/python/3.9.5/Python-3.9.5.tgz
Разархивируем:
tar xzf Python-3.7.9.tgz
tar xzf Python-3.8.9.tgz
tar xzf Python-3.9.5.tgz
Устанавливаем:
cd Python-3.7.9
./configure --enable-optimizations --prefix=/usr
make altinstall
cd ../Python-3.8.9
./configure --enable-optimizations --prefix=/usr
make altinstall
cd ../Python-3.9.5
./configure --enable-optimizations --prefix=/usr
make altinstall
Теперь установим плагин Pyenv Pipeline
Переходим в настройки Jenkins‘а
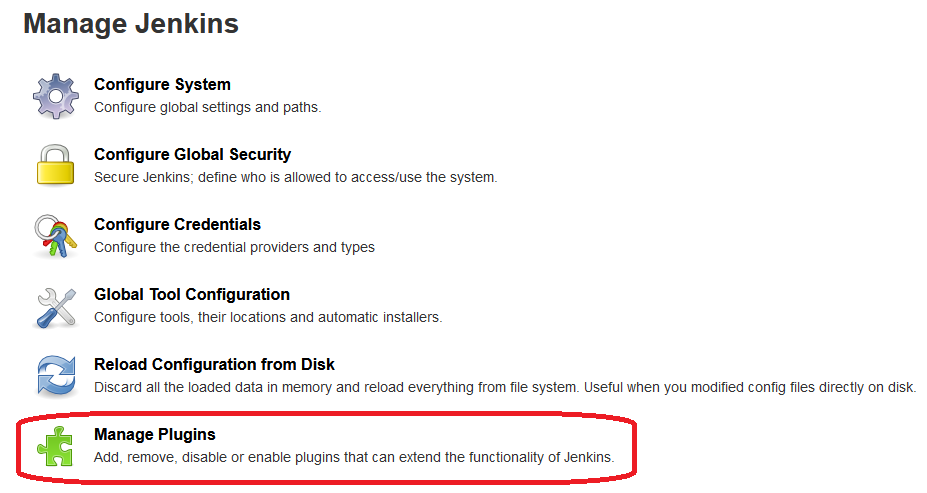
Раздел «Управление плагинами»
Переходим к вкладке «Доступные» и в поиске указываем «Pyenv Pipeline»

Устанавливаем его.
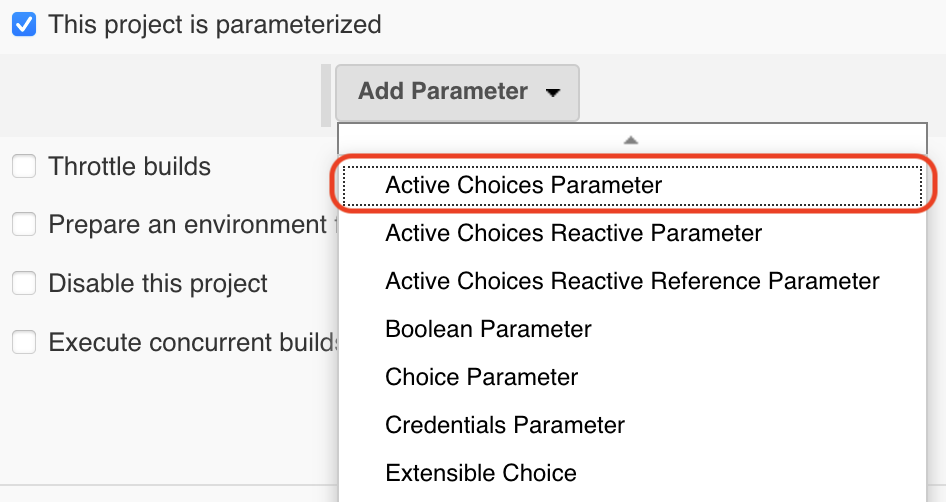
Для выбора версии будем использовать параметр «choice»
Pipeline:
properties([
parameters([
choice(
name: 'PYTHON',
description: 'Choose Python version',
choices: ["python2.7", "python3.6", "python3.7", "python3.8", "python3.9"].join("\n")
),
base64File(
name: 'REQUIREMENTS_FILE',
description: 'Upload requirements file (Optional)'
)
])
])
pipeline {
agent any
options {
buildDiscarder(logRotator(numToKeepStr: '5'))
timeout(time: 60, unit:'MINUTES')
timestamps()
}
stages {
stage("Python"){
steps{
withPythonEnv("/usr/bin/${params.PYTHON}") {
script {
if ( env.REQUIREMENTS_FILE.isEmpty() ) {
sh "python --version"
sh "pip --version"
sh "echo Requirements file not set. Run Python without requirements file."
}
else {
sh "python --version"
sh "pip --version"
sh "echo Requirements file found. Run PIP install using requirements file."
withFileParameter('REQUIREMENTS_FILE') {
sh 'cat $REQUIREMENTS_FILE > requirements.txt'
}
sh "pip install -r requirements.txt"
}
}
}
}
}
}
}
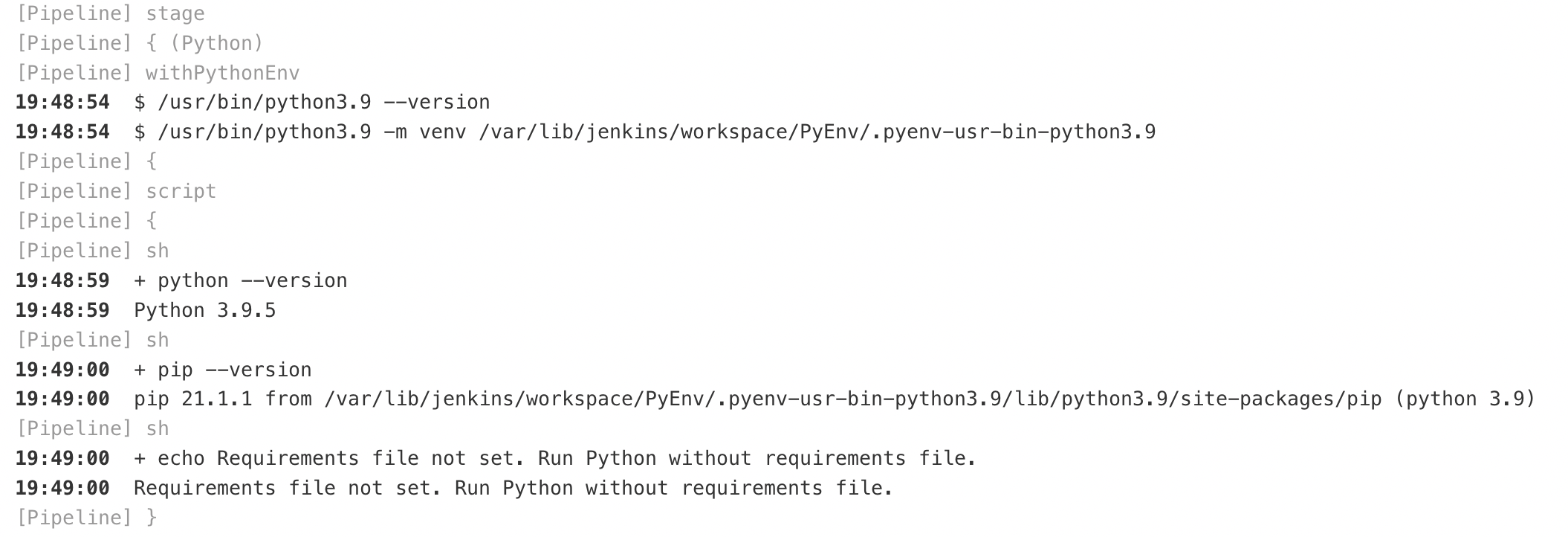
Запускаем сборку:

Выберем нужную версию, к примеру «3.9» и запустим сборку:
Проверим лог сборки: