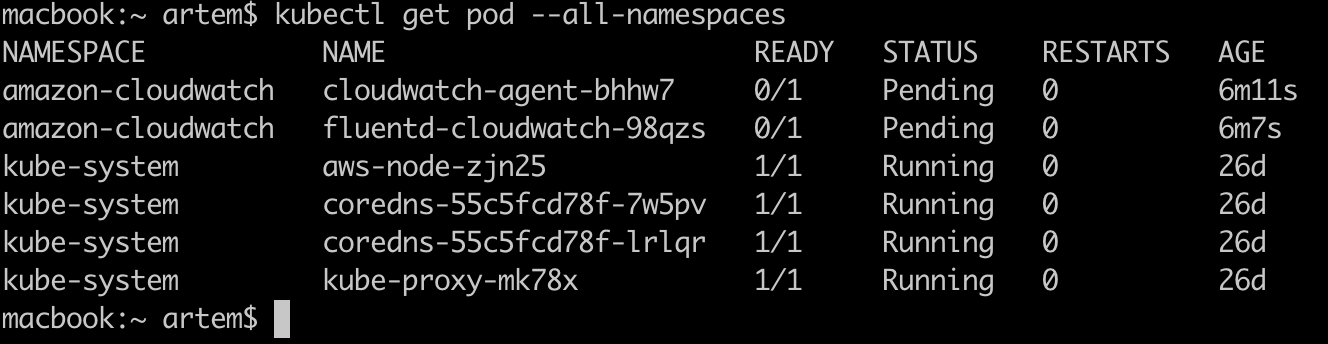
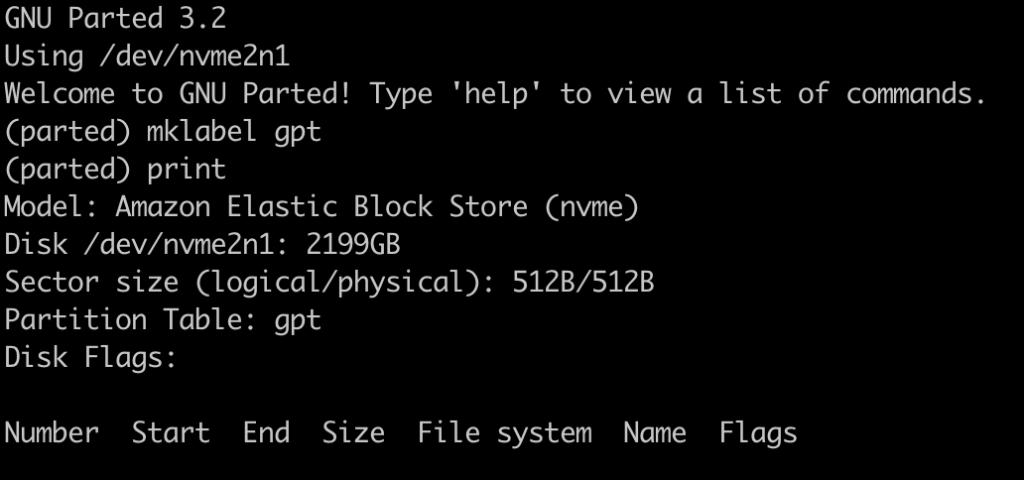
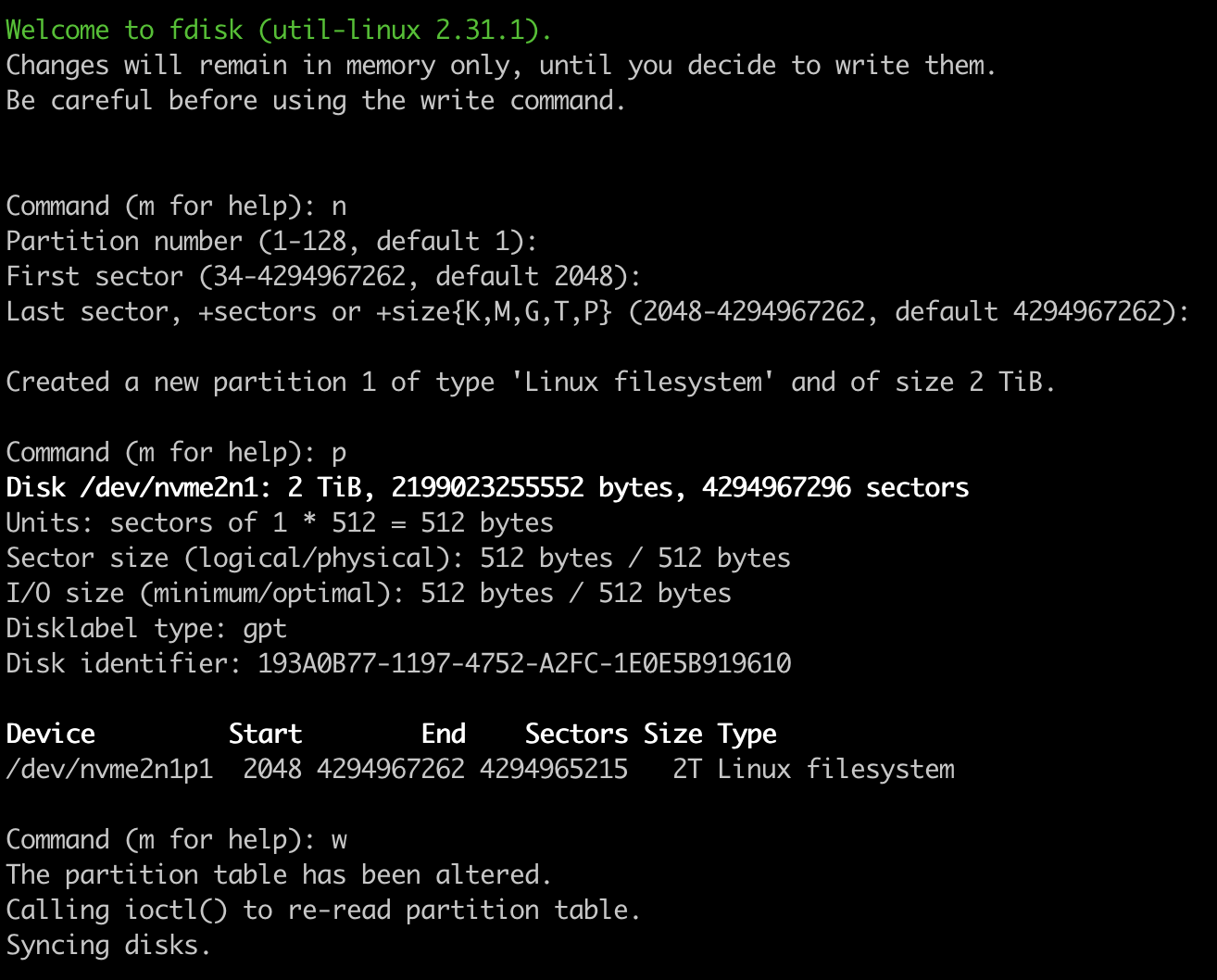
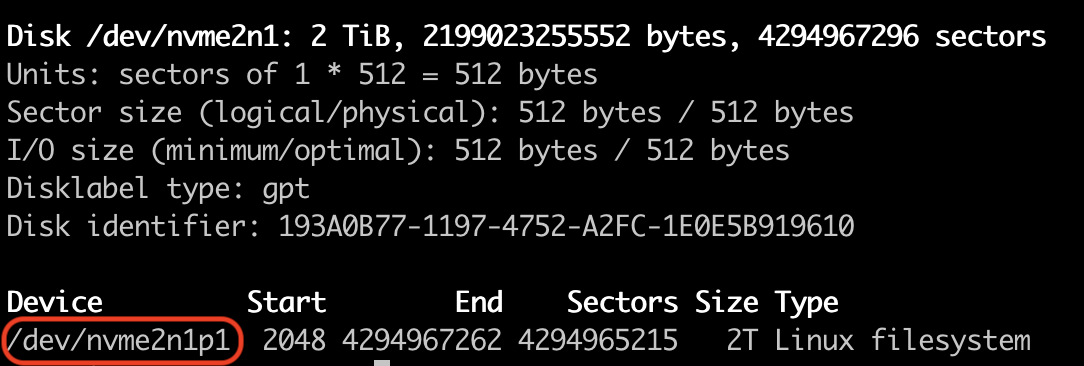
Для параметризованной сборки с выбором тега образа, понадобится плагин Active Choices
Переходим в настройки Jenkins‘а
Раздел «Управление плагинами»
Переходим к вкладке «Доступные» и в поиске указываем «Active Choices»

Устанавливаем его. Так же необходим плагин Amazon Web Services SDK
Создаем «New Item» — «Pipeline«, указываем, что это будет параметризованной сборка, и добавляем параметр «Active Choices Reactive Parameter»
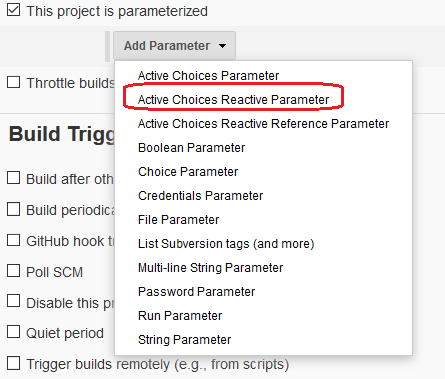
Указываем, что это «Groovy Script» и вставляем туда следующее:
import jenkins.model.*
import groovy.json.JsonSlurper
credentialsId = 'artem-github'
gitUri = '[email protected]:artem-gatchenko/ansible-openvpn-centos-7.git'
def creds = com.cloudbees.plugins.credentials.CredentialsProvider.lookupCredentials(
com.cloudbees.plugins.credentials.common.StandardUsernameCredentials.class, Jenkins.instance, null, null ).find{
it.id == credentialsId}
def slurper = new JsonSlurper()
def account = gitUri.split(":")[-1].split("/")[0]
def repo = gitUri.split(":")[-1].split("/")[-1].split("\\.")[0]
def addr = "https://api.github.com/repos/${account}/${repo}/commits"
def authString = "${creds.username}:${creds.password}".getBytes().encodeBase64().toString()
def conn = addr.toURL().openConnection()
conn.setRequestProperty( "Authorization", "Basic ${authString}" )
def response_json = "${conn.content.text}"
def parsed = slurper.parseText(response_json)
def commit = []
commit.add("Latest")
for (int i = 0; i < parsed.size(); i++) {
commit.add(parsed.get(i).sha)
}
return commit
Где значение переменных, «credentialsId» — Jenkins Credentials ID с токеном к GitHub‘у;
«gitUri» — полный путь к нужному репозиторию;
Тоже самое, но уже через Pipeline
Pipeline:
properties([
parameters([
[$class: 'StringParameterDefinition',
defaultValue: '[email protected]:artem-gatchenko/ansible-openvpn-centos-7.git',
description: 'Git repository URI',
name: 'gitUri',
trim: true
],
[$class: 'CascadeChoiceParameter',
choiceType: 'PT_SINGLE_SELECT',
description: 'Select Image',
filterLength: 1,
filterable: false,
referencedParameters: 'GIT_URI',
name: 'GIT_COMMIT_ID',
script: [
$class: 'GroovyScript',
script: [
classpath: [],
sandbox: false,
script:
'''
import jenkins.model.*
import groovy.json.JsonSlurper
credentialsId = 'artem-github'
def creds = com.cloudbees.plugins.credentials.CredentialsProvider.lookupCredentials(
com.cloudbees.plugins.credentials.common.StandardUsernameCredentials.class, Jenkins.instance, null, null ).find{
it.id == credentialsId}
def slurper = new JsonSlurper()
def account = gitUri.split(":")[-1].split("/")[0]
def repo = gitUri.split(":")[-1].split("/")[-1].split("\\\\.")[0]
def addr = "https://api.github.com/repos/${account}/${repo}/commits"
def authString = "${creds.username}:${creds.password}".getBytes().encodeBase64().toString()
def conn = addr.toURL().openConnection()
conn.setRequestProperty( "Authorization", "Basic ${authString}" )
def response_json = "${conn.content.text}"
def parsed = slurper.parseText(response_json)
def commit = []
commit.add("Latest")
for (int i = 0; i < parsed.size(); i++) {
commit.add(parsed.get(i).sha)
}
return commit
'''
]
]
]
])
])