For a parameterized assembly with an image tag selection, you will need the Active Choices plugin
Go to “Manage Jenkins”
Section “Manage Plugins”
Go to the “Available” tab and select “Active Choices” in the search.

Install it.
Create a “New Item” – “Pipeline“, indicate that it will be a parameterized assembly, and add the parameter “Active Choices Reactive Parameter”
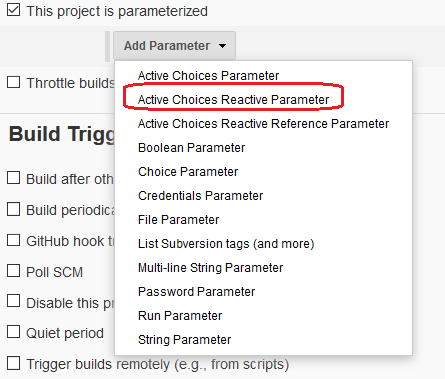
We indicate that this is “Groovy Script” and paste the following into it:
import jenkins.model.*
import groovy.json.JsonSlurper
credentialsId = 'artem-github'
gitUri = '[email protected]:artem-gatchenko/ansible-openvpn-centos-7.git'
def creds = com.cloudbees.plugins.credentials.CredentialsProvider.lookupCredentials(
com.cloudbees.plugins.credentials.common.StandardUsernameCredentials.class, Jenkins.instance, null, null ).find{
it.id == credentialsId}
def slurper = new JsonSlurper()
def account = gitUri.split(":")[-1].split("/")[0]
def repo = gitUri.split(":")[-1].split("/")[-1].split("\\.")[0]
def addr = "https://api.github.com/repos/${account}/${repo}/commits"
def authString = "${creds.username}:${creds.password}".getBytes().encodeBase64().toString()
def conn = addr.toURL().openConnection()
conn.setRequestProperty( "Authorization", "Basic ${authString}" )
def response_json = "${conn.content.text}"
def parsed = slurper.parseText(response_json)
def commit = []
commit.add("Latest")
for (int i = 0; i < parsed.size(); i++) {
commit.add(parsed.get(i).sha)
}
return commit
Where the value of variables, “credentialsId” – Jenkins Credentials ID with token to GitHub;
“gitUri” – the full path to the desired repository;
The same thing, but already in Pipeline
Pipeline:
properties([
parameters([
[$class: 'StringParameterDefinition',
defaultValue: '[email protected]:artem-gatchenko/ansible-openvpn-centos-7.git',
description: 'Git repository URI',
name: 'gitUri',
trim: true
],
[$class: 'CascadeChoiceParameter',
choiceType: 'PT_SINGLE_SELECT',
description: 'Select Image',
filterLength: 1,
filterable: false,
referencedParameters: 'GIT_URI',
name: 'GIT_COMMIT_ID',
script: [
$class: 'GroovyScript',
script: [
classpath: [],
sandbox: false,
script:
'''
import jenkins.model.*
import groovy.json.JsonSlurper
credentialsId = 'artem-github'
def creds = com.cloudbees.plugins.credentials.CredentialsProvider.lookupCredentials(
com.cloudbees.plugins.credentials.common.StandardUsernameCredentials.class, Jenkins.instance, null, null ).find{
it.id == credentialsId}
def slurper = new JsonSlurper()
def account = gitUri.split(":")[-1].split("/")[0]
def repo = gitUri.split(":")[-1].split("/")[-1].split("\\\\.")[0]
def addr = "https://api.github.com/repos/${account}/${repo}/commits"
def authString = "${creds.username}:${creds.password}".getBytes().encodeBase64().toString()
def conn = addr.toURL().openConnection()
conn.setRequestProperty( "Authorization", "Basic ${authString}" )
def response_json = "${conn.content.text}"
def parsed = slurper.parseText(response_json)
def commit = []
commit.add("Latest")
for (int i = 0; i < parsed.size(); i++) {
commit.add(parsed.get(i).sha)
}
return commit
'''
]
]
]
])
])