AWS Transfer поддерживает 3 протокола: SFTP, FTP и FTPS. И только SFTP может иметь публичный эндпоинт, FTP/FTPS можно запускать только внутри VPC. Так же для авторизации по логину/паролю, необходимо использовать кастомный провайдер, больше информации об этом вы можете найти тут.
Цель:
Создать AWS Transfer сервер для протокола FTP, сервис должен быть публичным и так же авторизация должна проходить по логину/паролю.
Протокол FTP является небезопасным, AWS не рекомендует его использовать в публичных сетях.
Первое что понадобится, это установленный AWS SAM CLI.
Создаем директорию, куда будем скачивать темплейт, переходим в нее и скачиваем:
wget https://s3.amazonaws.com/aws-transfer-resources/custom-idp-templates/aws-transfer-custom-idp-secrets-manager-sourceip-protocol-support-apig.zip
Разархивируем и выполняем следующую команду:
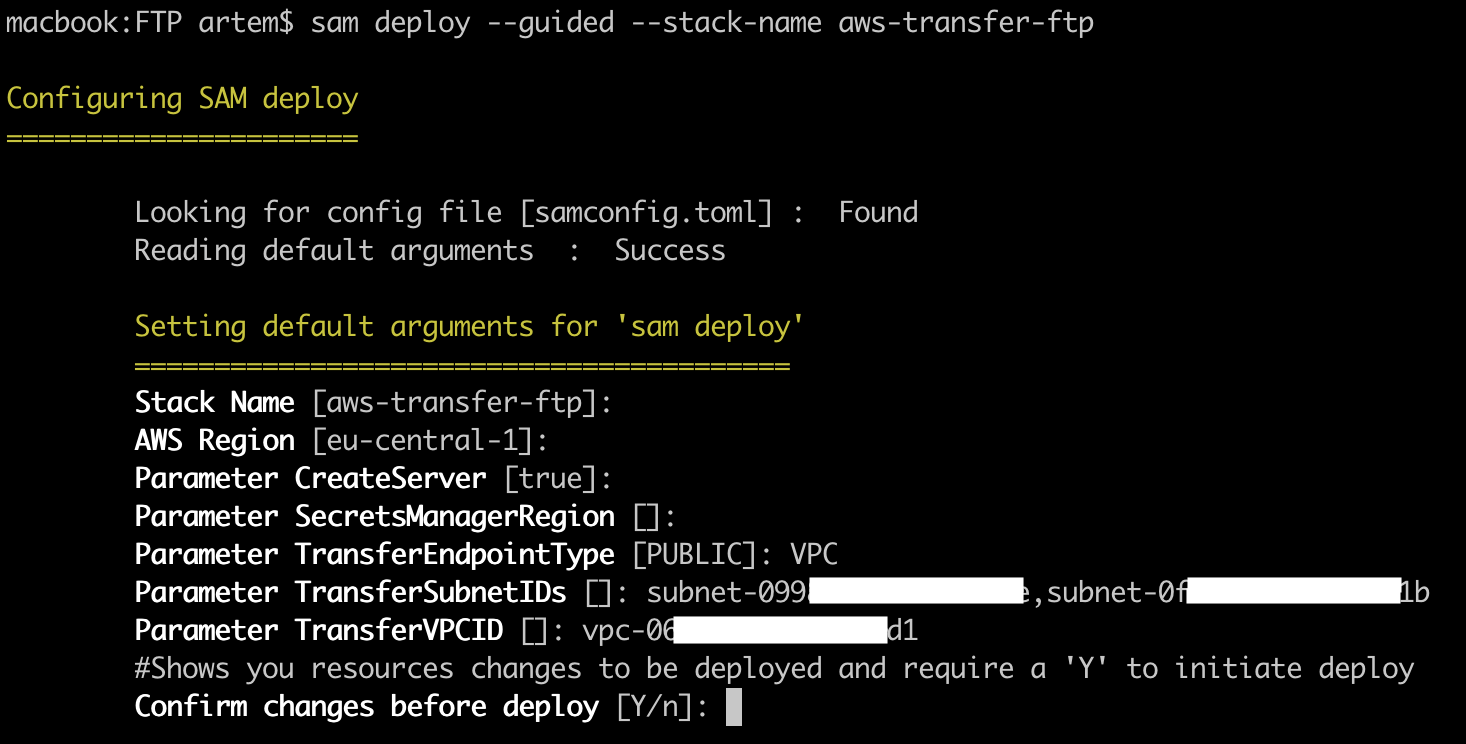
sam deploy --guided --stack-name aws-transfer-ftp
Где, "aws-transfer-ftp" — имя создаваемого CloudFormation стека, если укажите имя существующего, он его обновит.
После чего запустится интерактивная установка, где будет предложено указать следующие параметры:
- Stack Name — имя CloudFormation стека, по умолчанию берется параметр ключа "—stack-name";
- AWS Region — регион, в котором будет развернут CloudFormation стек;
- Parameter CreateServer — будет ли создан AWS Transfer сервис (по умолчанию — true);
- Parameter SecretManagerRegion — если ваш регион не поддерживает SecretsManager, то для него вы можете указать отдельный регион;
- Parameter TransferEndpointType — PUBLIC или VPC, так как FTP не поддерживает публичные эндпоинты, указываем VPC;
- Parameter TransferSubnetIDs — ID's сетей, в которых будет AWS Transfer эндпоинт;
- Parameter TransferVPCID — VPC ID, в которой находятся сети, указанные в предыдущем параметре.
Сразу создадим SecurityGroup для FTP сервиса в нужной VPC. И разрешим входящий траффик на TCP порты 21 и 8192—8200 с любого адреса. Пока сохраняем созданную SG, в дальнейшем мы ее приатачим.
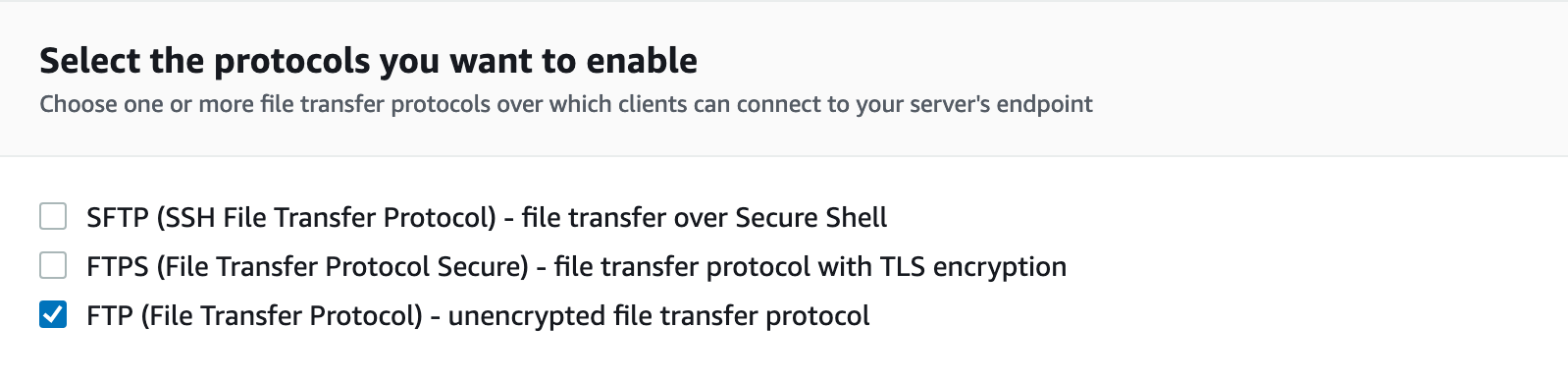
После чего переходим в AWS консоль — "AWS Transfer Family", находим созданный AWS Transfer сервер и редактируем его прокол, снимает галочку с протокола "SFTP" и ставим галочку напротив "FTP" протокола и сохраняем изменения.
Теперь нужно добавить доступ к FTP из мира, для этого будем использовать NLB. Для начала узнаем приватные IP адреса VPC эндпоинтов для AWS Transfer, для этого в блоке "Endpoint details" кликнем на ссылку на VPC эндпоинт.
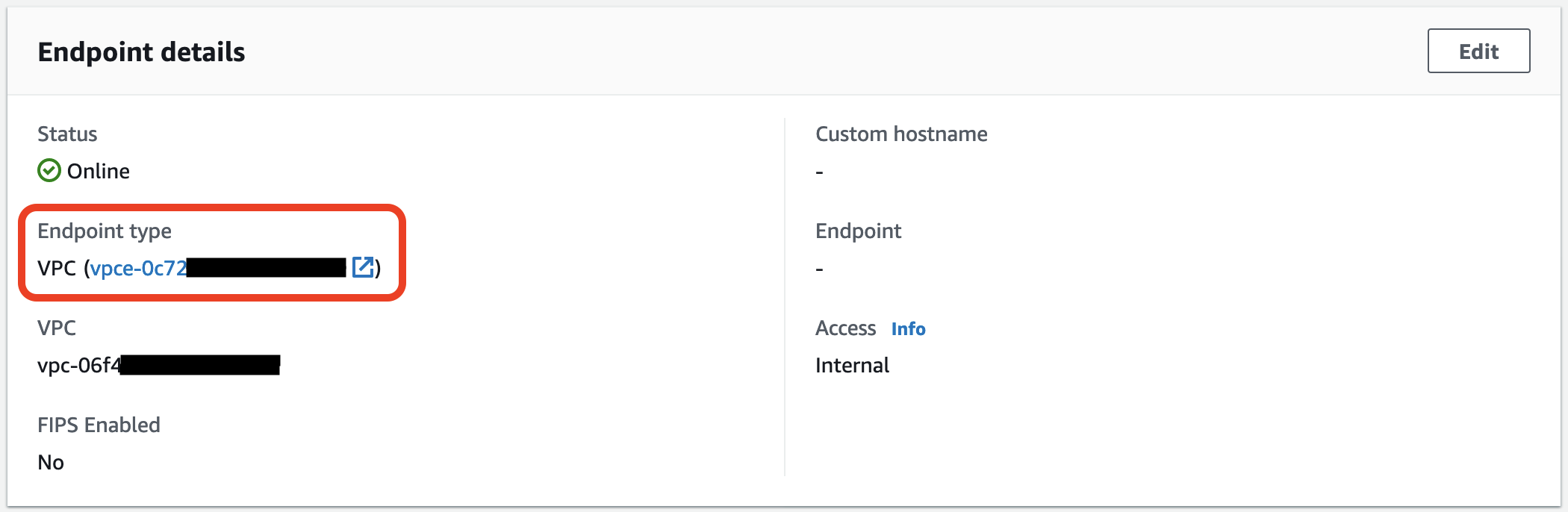
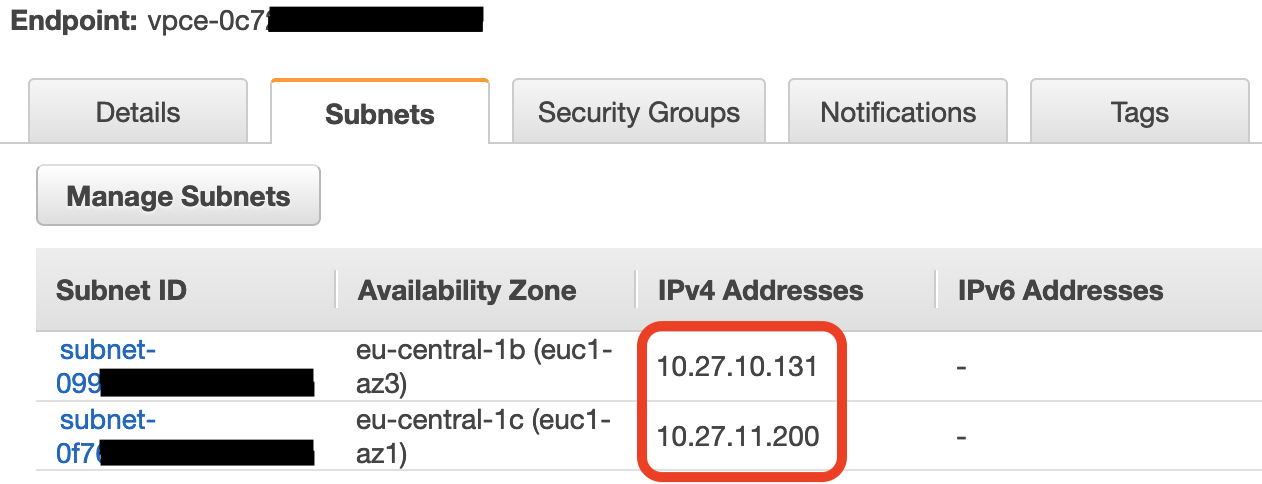
Переходим во вкладку "Subnets" и копируем все IP адреса, они понадобятся для создания таргет групп.
Тут же переходим во вкладку "Security Groups" и меняем дефолтную группу безопасности на созданную раннее.
Теперь создадим таргет группы, для это в AWS консоли переходим "EC2" -> "Load Balancing" -> "Target Groups" и создаем первую таргет группу для TCP 21 порта.
- Target type: IP address
- Protocol: TCP
- Port: 21
В названии таргет группы в конце лучше указать номер порта, так как их будет 10 и можно легко запутаться.
Так же укажем VPC, в которой был создан сервис AWS Transfer. В следующей вкладке один за одним укажем IP адреса VPC эндпоинта, которые мы смотрели раннее. Сохраняем таргет группу.
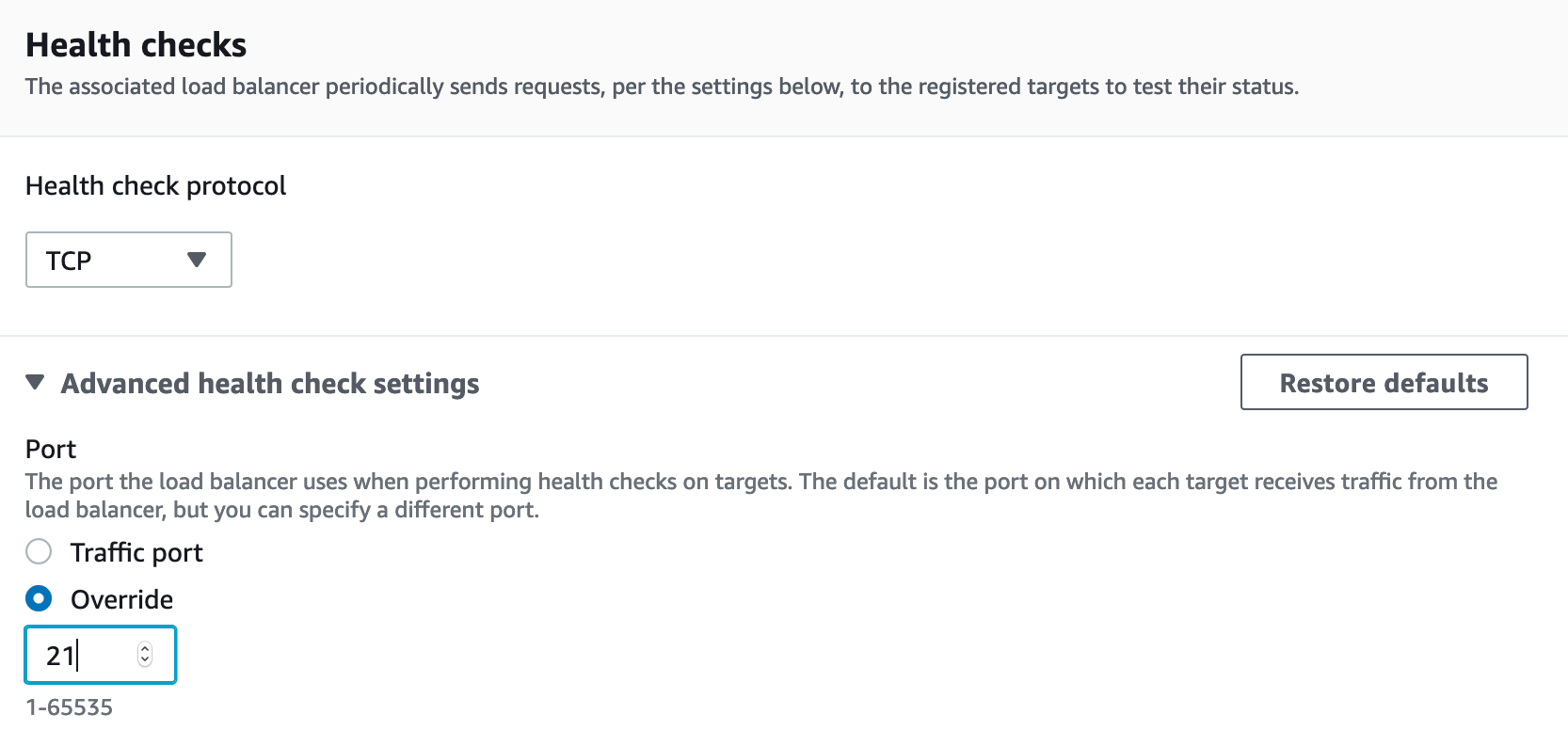
Теперь нужно создать еще 9 таргет групп, для диапазона портов: TCP 8192—8200. Процедура такая же, как для таргет группы для порта 21, за исключением того, что нужно HeathCheck порт указать 21. Для этого в блоке "Health checks" открываем вкладку "Advanced health check setting", выбираем "Overrive" и указываем номер порта — 21.
После того, как закончили с таргет группами, нужно создать Network Load Balancer с типом "internet-facing" и разместить его в публичных сетях той же VPC, где и AWS Transfer сервис. Так же создаем 10 листенеров, для TCP портов 21-го, и диапазона 8192—8200, и для каждого листенера указываем нужную таргет группу, соответствующую номеру порта. После чего FTP сервис должен быть доступ из вне.
Для того, чтобы добавить FTP пользователя нужно в AWS консоли перейти в "Secrets Manager" и создать секрет с типом "Other type of secrets"
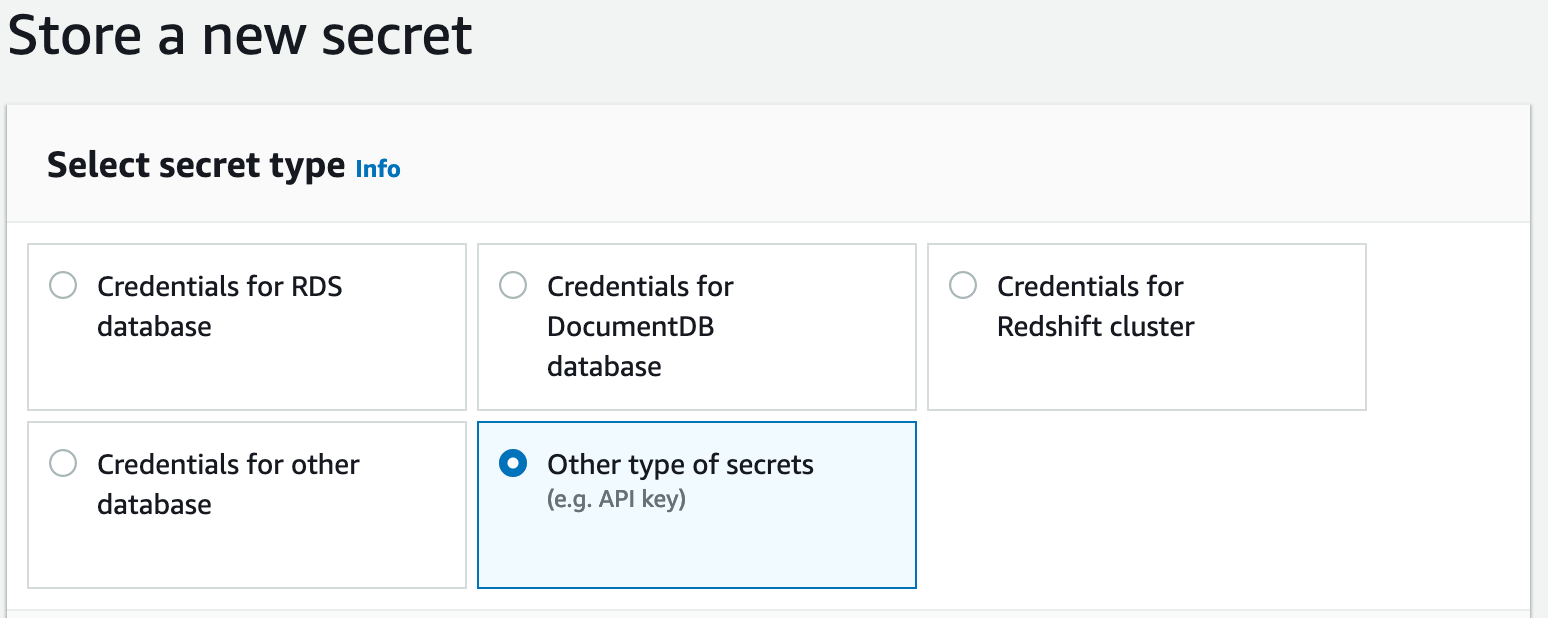
Создаем 3 пары "key/value":
- Password — пароль для нового FTP пользователя;
- Role — ARN роли, у которой есть права записи в нужный S3 бакет;
- HomeDirectoryDetails — [{"Entry": "/", "Target": "/s3-bucket/user-name"}]
Где "s3-bucket" — имя S3 корзины, "user-name" — имя директории, в которую будет попадать пользователь при подключении к FTP серверу (имя директории не обязательно должно соответствовать имени пользователя, и так же может находится не в корне корзины)
Сохраняем секрет обязательно с именем в формате: "server_id/user_name", где "server_id" — это ID сервера AWS Transfer, "user_name" — имя пользователя, которое будет использоваться для подключения к FTP серверу.
Так же для удобства можно создать DNS CNAME запись на NLB запись.